

We are busy working on making HLS playback within the Brightcove Player better, faster, and more stable. To do that, we have had to throw out our assumptions and start looking at the problem we were facing without any preconceptions.
THE CHALLENGE
One of the primary responsibilities of any playback engine that leverages Media Source Extensions (MSE) is to make decisions about what video data (termed segments or fragments) to request from the server at any given time.
With video on demand (VOD) HLS sources, the decisions are fairly simple. We know about all the segments and (roughly) their durations. Making a choice about which segment to download given that information is straightforward.
Unfortunately, things aren’t so simple in a live HLS stream. Not only do we lack the entire history of segments, but without the PROGRAM-DATETIME tag in HLS (a recent addition to the HLS specification), we also don’t have any easy way to correlate segments across variant playlists. The only option left to the player is to speculatively download segments in order to use the internal timestamps of the media.
In short, the problem with live playback is that there are times where the many “unknowns” make selecting the correct segment the first time a difficult task.
FETCH ALGORITHM
To combat the tendency of any fetch algorithm to select the wrong segment, we borrowed some concepts from control theory. Previously, the fetch algorithm would:
- Make the best guess possible given the limited information
- If the guess was wrong, use the information gained from that request to make a better guess (lower the “error”)
- Repeat
The hope was that the algorithm would iteratively improve and eventually download the correct segment. The problem comes about when you start to consider what an “error” is. For our algorithm, we defined error as a region of the video buffer that was missing data.
The thinking here is that if we fetched segment A followed by segment C, we would have created a B-sized gap that would need to be filled. The algorithm should then backtrack to fill that error and select segment B before continuing forward to D.
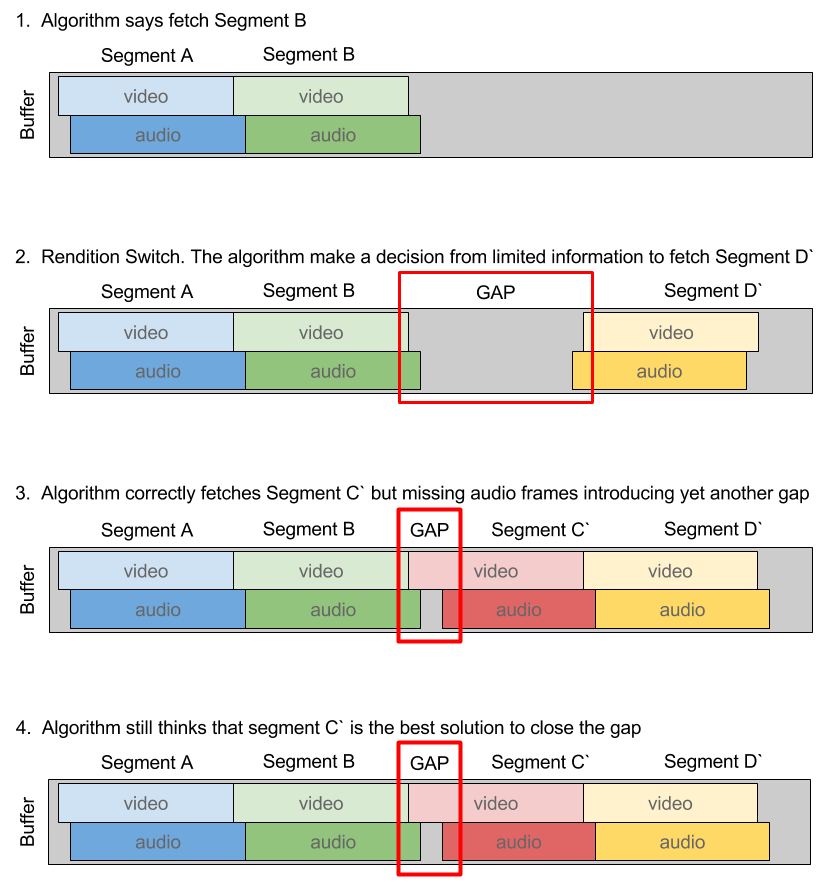
The good news is that 99% of the time this worked and worked quite well. The bad news is that 1% of the time it would got stuck trying to fill a gap that was essentially unfillable. When this happened it was usually due to nature of the sources we were playing. Some HLS sources are poorly segmented so that audio and video aren’t segmented at the same point in time across all variants, leading to gaps. Some HLS sources have corrupt or missing frames (audio or video) which also cause gaps.
Whatever the cause, these unfillable parts of the buffer created situations where the algorithm was stuck trying to fill it. We eventually built in many approaches to try and keep the fetcher from getting stuck:
- Consider very small gaps as something intrinsic to the source and ignore them
- Force the algorithm to fetch one or more segments forward if it ever tried to fetch the same segment as it did during the last iteration
- Considering segments whose bounds were 90% or more represented in the buffer as loaded to avoiding wasting unnecessary bandwidth
The problem with each of these strategies is that they have very specific circumstances under which they breakdown. With each “fix,” we attempted the number of corner-cases was multiplying. In many cases, we discovered that even small changes to the fetch algorithm failed under odd scenarios that previously worked.
STARTING FRESH
All these problems led us to one inescapable conclusion: We needed a drastic change to our approach. Examining the problem, we realized that we had a lot of assumptions about the way the fetch algorithm should function that made things more difficult on us.
One of those assumptions was that the fetch algorithm should always avoid requesting segments that were already buffered. The problem is that the state of the buffer is very hard to reason about once you combine the effects of seeking, buffer garbage collection (something MSE does automatically behind the scenes), and sources that naturally introduce gaps. In the end, it meant that our algorithm was inextricably reliant on MSE’s ever changing buffer.
The new fetcher does away with this and many other assumptions in order to simplify things as much as possible. For example, the player now cleans up the buffer after every seek so that the state of the buffer is easier to reason about and doesn’t try to guard against loading a segment that is already present in the buffer.
WALKING THE WALK
After re-examining our assumptions we realized that making an accurate guess 100% of the time is impossible but making a conservative guess 100% of the time is entirely possible. A conservative guess is one that is the segment at or before the desired segment. Making a conservative guess means that you can always find the right segment by simply walking forward through the segments in a playlist.
With this understanding, we drastically change the nature of the problem. Now, we are always fetching contiguous regions after making an initial guess. That means that details about the state of the buffer—gaps—are no longer a concern to us since they are, by definition, intrinsic to the media and not due to the behavior of the fetching algorithm.
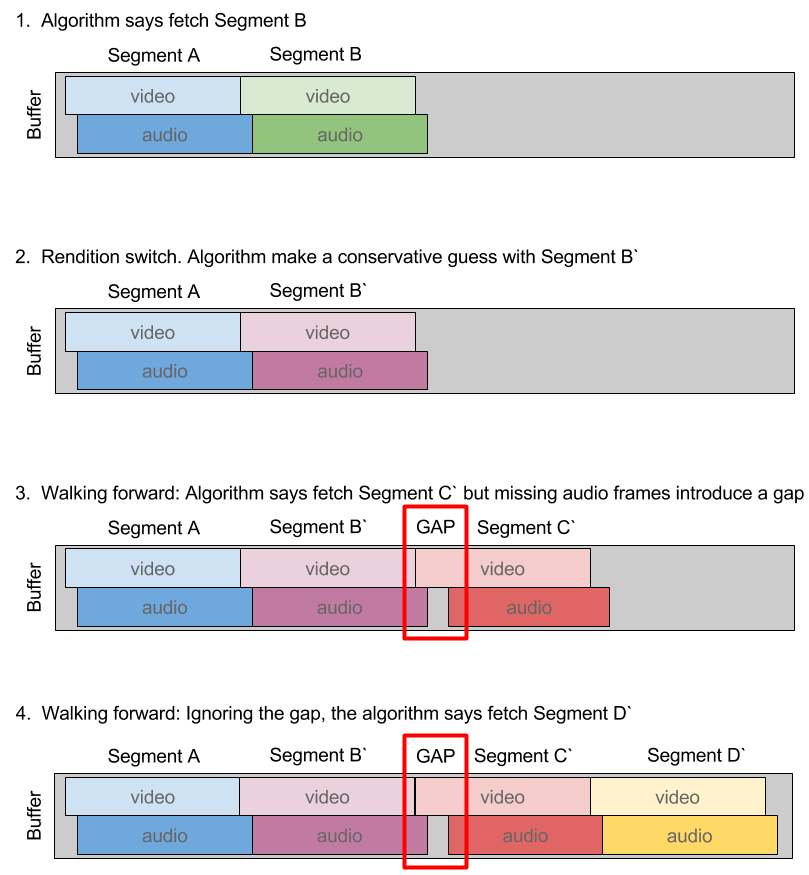
The only remaining question was how do we correlate segments and times between variants in a live playlist. For this purpose, we introduce the concept of a “sync-point.” A sync-point is defined as a known mapping between a segment index and a display-time—the time you get from calling player.currentTime().
The new fetch algorithm has just three modes of operation:
- Conservatively guessing which segment to start downloading from
- Simply walking forward through the playlist
- Attempting to create a sync-point
That last state is only ever entered when the fetcher can’t use any of the information it has saved to make a guess. It is a rare event but when that happens, we must download a segment – any segment – and utilize the internal timestamps in the media to generate a “sync-point” which the fetch algorithm can then use to make a conservative guess before walking forward.
The end result of these changes is an improved HLS playback experience. Live playback in particular should start more quickly and play more reliably.


