

At Brightcove, we use Amazon S3 as part of our video player delivery, publishing, and player management solutions – and rightfully so as it’s a leader in the space and delivers great performance. Great performance does not make it infallible, however. We’ve spent a lot of time and effort hardening our services to withstand an outage in anticipation of such an event and our efforts have paid off.
AMAZON S3 SERVICE INCIDENT
On Thursday September 14th, 2017, for a brief period around 1:37 PM EDT and then for about an hour beginning at 2:40 PM EDT, the Amazon S3 service began unwarrantedly throttling requests in the U.S. East region. As a result, it was rejecting a lot of perfectly valid requests to get and put files.
Many S3 customers were impacted, including some of the most visited websites on the internet that rely on this highly-reliable cloud infrastructure. While Brightcove did have an increase in error rates for some cold cache video content, we are happy to report that player loads, whether cached or uncached, went unaffected. What could have been a much bigger event was very much contained.
Here is some info about the incident as reported by The Register. The information that Amazon shared during the incident was as follows (times adjusted to EDT):
- 2:58 PM EDT. We are investigating increased error rates for Amazon S3 requests in the US-EAST-1 Region.
- 3:20 PM EDT. We can confirm that some customers are receiving throttling errors accessing S3. We are currently investigating the root cause.
- 3:38 PM EDT. We continue to work towards resolving the increased throttling errors for Amazon S3 requests in the US-EAST-1 Region. We have identified the subsystem responsible for the errors, identified root cause and are now working to resolve the issue.
- 3:49 PM EDT. We are now seeing recovery in the throttle error rates accessing Amazon S3. We have identified the root cause and have taken actions to prevent recurrence.
- 4:05 PM EDT. Between 2:40 PM and 3:56 PM EDT we experienced throttling errors accessing Amazon S3 in the US-EAST-1 Region. The issue is resolved and the service is operating normally.
At 1:37 PM, well before the Amazon acknowledgement, the first errors triggered our alerts. Rather than tell us that there was a problem with our services, the alerts told us that corrective action had automatically kicked in.
During this entire incident, which occurred at peak-times for Brightcove, we responded to more than 28 million requests for the Brightcove Player without issue. This included players that were already active as well as 79 players that were published during the incident.
PLAYER FAILOVER TACTICS
Here is a glimpse of what our S3 setup looks like.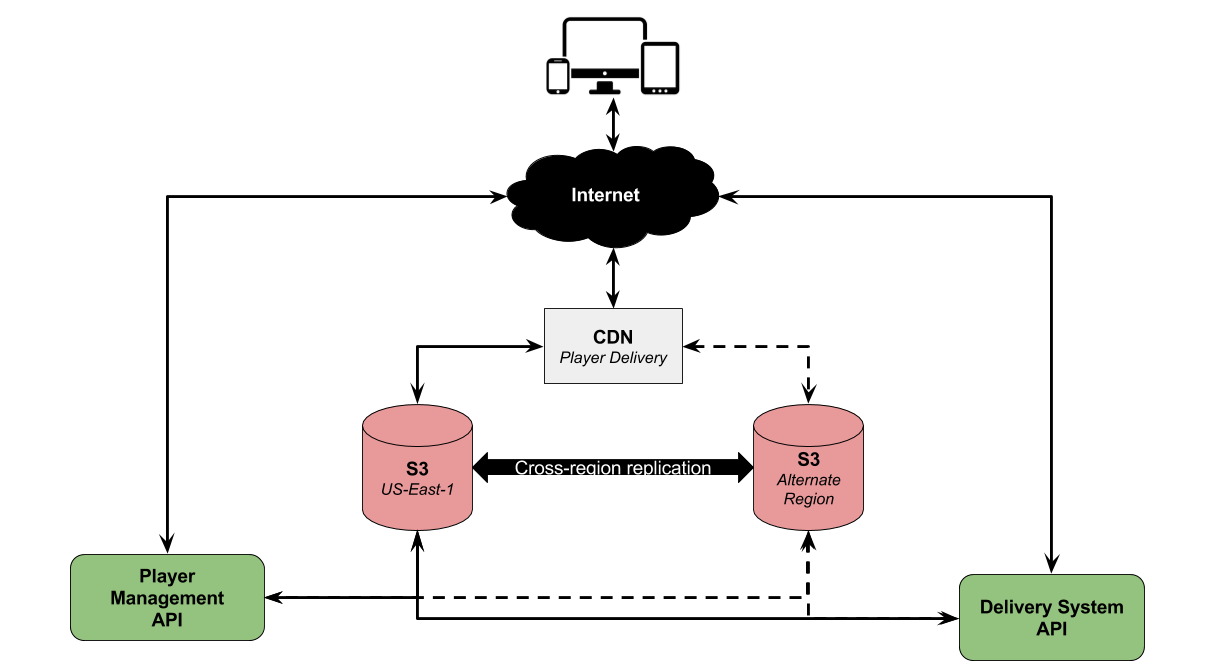
Although we do use S3 in the U.S. East region (where the incident occurred), we have implemented bi-directional cross-region replication options provided by Amazon.
We have also created our own open source Node.js project called s3-s3 which handles automatic switching to different S3 buckets as needed. This means that under normal operating conditions every file that we upload to U.S. East is also sent to our failover region.
Every time the Player Management and Publishing services interact with S3, they are ready for the worst. If there is an error, we automatically retry and if the retries fail, then we automatically failover to another region.
We handle failover at the individual request level. Requests always start with the primary region and fall back to the failover region if necessary. There is no need for manual intervention to switch systems over or back.
Thanks to our bi-directional replication, any files that must be pushed up to the failover region will be automatically replicated back to U.S. East when it is healthy again.
The graph below shows our automatic failover in action. The services continued to use our primary S3 bucket as often as possible but did end up failing over quite a bit in the process. The alternative: All of the requests on the right would have failed causing issues for our customers.

So if you were blissfully unaware that there were any Amazon problems happening, that’s how we like it.


