I became interested in finding The Perfect Load Balancer when we had a series of incidents at work involving a service talking to a database that was behaving erratically. While our first focus was on making the database more stable, it was clear to me that there could have been a vastly reduced impact to service if we had been able to load-balance requests more effectively between the database’s several read endpoints.
The more I looked into the state of the art, the more surprised I was to discover that this is far from being a solved problem. There are plenty of load balancers, but many use algorithms that only work for one or two failure modes—and in these incidents, we had seen a variety of failure modes.
This post describes what I learned about the current state of load balancing for high availability, my understanding of the problematic dynamics of the most common tools, and where I think we should go from here.
(Disclaimer: This is based primarily on thought experiments and casual observations, and I have not had much luck in finding relevant academic literature. Critiques are very welcome!)
TL;DR
Points I’d like you to take away from this:
- Server health can only be understood in the context of the cluster’s health
- Load balancers that use active healthchecks to kick out servers may unnecessarily lose traffic when healthchecks fail to be representative of real traffic health
- Passive monitoring of actual traffic allows latency and failure rate metrics to participate in equitable load distribution
- If small differences in server health produce large differences in load balancing, the system may oscillate wildly and unpredictably
- Randomness can inhibit mobbing and other unwanted correlated behaviors
FOUNDATIONS
A quick note on terminology: In this post, I’ll refer to clients talking to servers with no references to “connections,” “nodes,” etc. While a given piece of software can function as both a client and a server, even at the same time or in the same request flow, in the scenario I described the app servers are clients of the database servers, and I’ll be focusing on this client-server relationship.
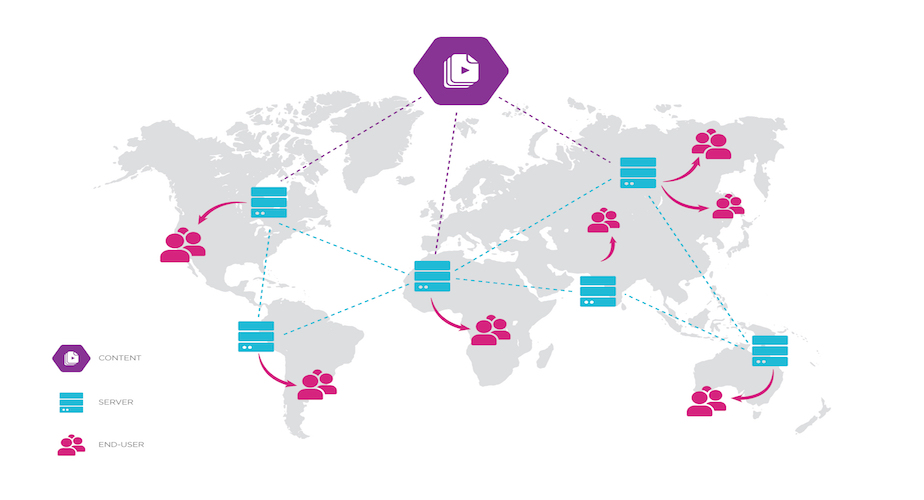
So in the general case we have N clients talking to M servers:

I’m also going to ignore the specifics of the requests. For simplicity, I’ll say that the client’s request is not optional and that fallback is not possible; if the call fails, the client experiences a degradation of service.
The big question, then, is: When a client receives a request, how should it pick a server to call?
(Note that I’m looking at requests, not long-lived connections which might carry steady streams, bursts of traffic, or requests at varying intervals. It also shouldn’t particularly matter to the overall conclusions whether there is a connection made per request or whether they re-use connections.)
You might be wondering why I have every client talking to every server, commonly called “client-side load balancing” (although in this post’s terminology, the load balancer is also called a client.) Why make the clients do this work? It’s quite common to put all the servers behind a dedicated load balancer.

The catch is that if you only have one dedicated load balancer node, you now have a single point of failure. That’s why it’s traditional to stand up at least three such nodes. But notice now that clients now need to choose which load balancer to talk to… and each load balancer node still needs to choose which server to send each request to! This doesn’t even relocate the problem, it just doubles it. (“Now you have two problems.”)
I’m not saying that dedicated load balancers are bad. The problem of which load balancer to talk to is conventionally solved with DNS load balancing, which is usually fine, and there’s a lot to be said for using a more centralized point for routing, logging, metrics, etc. But they don’t really allow you to bypass the problem, since they can still fall prey to certain failure modes, and they’re generally less flexible than client-side load balancing.
VALUES
So what do we value in a load balancer? What are we optimizing for?
In some order, depending on our needs:
- Reduce the impact of server or network failures on our overall service availability
- Keep service latency low
- Spread load evenly between servers
- Don’t overly stress a server if the others have spare capacity
- Predictability: Easier to see how much headroom the service has
- Spread load unevenly if servers have varying capacities, which may vary in time or by server (equitable distribution, rather than equal distribution)
- A sudden spike, or large amount of traffic right after server startup, might not give the server time to warm up. A gradual increase to the same traffic level might be just fine.
- Non-service CPU loads, such as installing updates, might reduce the amount of CPU available on a single server.
NAÏVE SOLUTIONS
Before trying to solve everything, let’s look at some simplistic solutions. How do you distribute requests evenly when all is well?
- Round-robin
- Client cycles through servers
- Guaranteed even distribution
- Random selection
- Statistically approaches an even distribution, without keeping track of state (coordination/CPU tradeoff)
- Static choice
- Each client just chooses one server for all requests
- DNS load balancing effectively does this: Clients resolve the service’s domain name to one or more addresses, and the client’s network stack picks one and caches it. This is how incoming traffic is balanced for most dedicated load balancers; their clients don’t need to know there are multiple servers.
- Sort of like random, works OK when 1) DNS TTLs are respected and 2) there are significantly more clients than servers (with similar request rates)
And what happens if one of the servers goes down in such a configuration? If there are 3 servers, then 1 in 3 requests fail. A 67% success rate is pretty bad. (Not even a single “nine”!) The best possible success rate in this scenario, assuming a perfect load balancer and sufficient capacity on the two remaining servers, is 100%. How can we get there?

DEFINING HEALTH
The usual solution is healthchecks. Healthchecks allow a load balancer to detect certain server or network failures and avoid sending requests to servers that fail the check.
In general, we wish to know how “healthy” each server is, whatever that means, because it may have predictive value in answering the core question: “Is this server likely to give a bad response if I send it this request?” There’s a higher level question, too: “Is this server likely to become unhealthy if I send it more traffic?” (Or return to health, if I send it less.) Another way of saying this is that some cases of unhealthiness may be dependent on load, while others are load-independent; knowing the difference is essential to predicting how to route traffic when unhealthiness is observed.
So broadly speaking, “health” is really a way of modeling external state in service of prediction. But what counts as unhealthy? And how do we measure it?
CHOOSING A VANTAGE POINT
Before going into details, it’s important to note that there are two very different viewpoints we can use:
- The intrinsic health of the server: Whether the server application is running, responding, able to talk to all of its own dependencies, and not under severe resource contention.
- The client’s observed health of the server: The health of the server, but also the health of the server’s host, the health of the intervening network, and even whether the client is configured with a valid address for the server.
From a practical point of view, the server’s intrinsic health doesn’t matter if the client can’t even reach it. Therefore, we’ll mostly be looking at server health as observed from the client. There’s some subtlety here, though: As the request rate to the server increases, the server application is likely to be the bottleneck, not the network or the host. If we start seeing increased latency or failure rate from the server, that might mean the server is suffering under request load, implying that an additional request burden could make its health worse. Alternatively, the server might have plenty of capacity, and the client is only observing a transient, load-independent network issue, perhaps due to some non-optimal routing. If that’s the case, then additional traffic load is unlikely to change the situation. Given that in the general case it can be difficult to distinguish between these cases, we’ll generally use the client’s observations as the standard of health.
WHAT IS THE MEASURE OF HEALTH?
So, what can a client learn about a server’s health from the calls it is making?
- Latency: How long does it take for responses to come back? This can be broken down further: Connection establishment time, time to first byte of response, time to complete response; minimum, average, maximum, various percentiles. Note that this conflates network conditions and server load—load-independent and load-dependent sources, respectively (for the majority of cases.)
- Failure rate: What fraction of requests end in failure? (More on what failure means in a bit.)
- Concurrency: How many requests are currently in flight? This conflates effects from server and client behavior—there may be more in-flight requests to one server either because the server is backed up or because the client has decided to give it a larger proportion of requests for some reason.
- Queue size: If the client maintains a queue per server rather than a unified queue, a longer queue may be an indicator of either bad health or (again) unequal loading by the client.
With queue size and concurrent request count we see that not all measurements are of health per se, but can also be indicative of loading. These are not directly comparable, but clients presumably want to give more requests to healthier and less-loaded servers, so these metrics can be used alongside more intrinsic ones such as latency and failure rate.
These are all measurements made from the client’s perspective. It’s also possible to have the server self-report utilization, although that largely won’t be covered in this post.
All of these can also be measured across different time intervals: Most recent value, sliding window (or rolling buckets), decaying average, or several of these in combination.
DEFINING FAILURE
Of these health indicators, failure rate is perhaps of highest significance: For most use cases, a caller would rather get a slow success than a failure of any sort. But there are different kinds of failure, and they can imply different things about the state of the server.
If a call times out, there might be networking or routing issues causing high latency, or the server might be under heavy load. But if the call fails fast, there are very different implications: DNS misconfiguration, broken server, bad route. A fast failure is less likely to be load-dependent, unless perhaps the server is using load-shedding to intentionally fail fast under heavy load—in which case it’s possible that it will not be further stressed by more load.
If you look at application-level failures, not just transport-level failures, it is critical to be careful in choosing your criteria for marking a call as failed. For example, an HTTP call that fails to return (due to timeout, etc.) is unambiguously a failure, but a well-formed response with an error status code (4xx or 5xx) may not indicate a server problem. An individual request may be triggering a data-dependent 500 Server Error that is not representative of overall server health. It’s common to see a burst of 404 or 403 responses due to a caller with badly formed requests, but only that caller is affected; judging the server unhealthy only on that basis would be unwise. On the other hand, it is somewhat less likely for a read timeout to be specific to a bad request.
WHAT ABOUT HEALTHCHECKS?
So far we’ve mostly been talking about ways in which a client can passively glean information about server health from requests that it is already making. Another approach is to use active healthchecks.
AWS’s Elastic Load Balancer (ELB) healthchecks are an example of this. You can configure the load balancer to call some HTTP endpoint on each server every 30 seconds, and if the ELB gets a 5xx response or timeout 2 times in a row, it takes the server out of consideration for normal requests. It keeps making the healthcheck calls, though, and if the server responds normally 10 times in a row, it is put back in the rotation.
This demonstrates the use of hysteresis to ensure that the host doesn’t flap in and out of service too readily. (A familiar example of hysteresis is the way an air conditioner’s thermostat maintains a “window of tolerance” around the desired temperature.) This is a common approach, and it can work reasonably well for scenarios where a server is either all the way healthy or unhealthy, and does not change state frequently. In the less common situation of persistent, low failure rates below about 40% that affect both the healthcheck and the normal traffic, an ELB under default configuration would not see consecutive failures frequently enough to keep the host out of service.
Healthchecks need to be designed carefully lest they have the wrong effect on the load balancer. Here are some of the types of answers a healthcheck call might be intended to provide:
- Smoke test: Make one realistic call and see if the expected response comes back
- Functional dependency check: Server makes calls to all of its dependencies and returns a failure if any of them fail
- Availability check: Just see if the server can respond to any call, e.g.
GET /ping yields 200 OK and a response body of pong
It’s important that the healthcheck be as representative as possible of real traffic. Otherwise, it may yield unacceptable false positives or false negatives. For instance, if the server has a number of API routes, and only one of those routes is broken due to a failed dependency… is that server healthy? If your smoke test healthcheck only hits that route, your client will see the server as entirely broken; alternatively, if that route is the only one that is working, your client may see the server as perfectly healthy.
Functional checks can be more comprehensive, but this is not necessarily better, since this can easily result in a server (or all servers!) being marked as down if even a single, optional dependency is down. That’s useful for operational monitoring, but dangerous for load balancing; as a result, many people just configure simple availability checks.
Active healthchecks generally provide a binary view of the health of a server, even if tracked over time, since a server may be in a degraded state where it can consistently answer some requests but not others. Passively monitoring traffic health, on the other hand, gives a scalar (or even more nuanced) view of health, since at the very least the client knows what proportion of the requests are receiving failures—and critically, this passive monitoring receives a comprehensive view of traffic health. (Both types of check can track latency information, of course; some of these distinctions only hold for the failure rate metric.)
BINARY HEALTHCHECKS AND ANOMALY DETECTION
This binary view can lead to serious trouble since it doesn’t allow health comparison across servers. They’re simply grouped as “up” or “down,” based on a single call type which may not be representative. Even if you had multiple health check calls, there’s no guarantee they stay representative of your server’s health as its API expands and as client needs change. But even worse, correlated failures could lead to an unnecessary cascading failure. Look at these scenarios:
- If 100% of your hosts have passing active healthchecks, an ideal load balancer should route to all hosts.
- If 90% are passing, route to just those 90%—it doesn’t matter why the 10% are failing, since the rest of the cluster can undoubtedly handle the load.
- If only 10% are passing… route to all hosts—better to bet on the healthcheck being wrong (or irrelevant) rather than crushing the 10% that are passing checks.
- If 0% are passing, route to all hosts—you fail 100% of the requests you don’t route, as they say.
The closer the passing fraction of hosts gets to zero, the more likely it is that there’s a failure in something external to the hosts, or even something wrong with the healthcheck. Imagine that your healthcheck depends on a test account, and the test account is deleted. Or perhaps one dependency goes down, but most requests can still be served. Nevertheless, all healthchecks fail; the ELB takes every single one of your hosts out of service, even though incoming requests were being serviced perfectly fine.
What’s clear from this is that health is relative: A server can be healthier than its neighbors even if all of them have a problem. And it’s easier to see that when using scalars instead of booleans.
Essentially, you’d like your load balancer to be performing some kind of simple anomaly detection. If a small fraction of your servers are behaving oddly, just exclude them and send a heads-up to Ops. If most or all are behaving oddly? Don’t make things worse by putting all the load on a small handful of servers—or even worse, none of them.
The key, here, is to evaluate server health in view of the entire cluster, rather than atomically. The closest I’ve seen to this so far is Envoy’s load balancer, which has a “panic threshold” that by default will keep all hosts in service if 50% or more of them have failing healthchecks. If you’re using healthchecks in your load balancer, consider using such an approach.
You may notice that I’ve skipped over the question of what to do when 30–70% of servers are failing checks. This situation may indicate a true failure, and may be either load-dependent or load-independent. I’m not sure it is possible for a load balancer to know which situation applies, even if it is willing to do clever A/B traffic load experiments to find out. Even worse, putting all the load on a relatively small number of servers may take those servers down. Besides load-shedding, there’s not much that can be done in this situation, and I’m not sure I could fault either a design that keeps those servers in service, or one that takes them out, when within that middle range—because I’ve been one of the humans in the loop during such a production incident, and it wasn’t clear to us at the moment either.
Another difference between these active and passive approaches is that with active checking, information about server health is updated at a steady rate, regardless of traffic rate. This can be an upside when traffic is slow, or a downside when it is high. (Five seconds of failures can be a long time when you have 10,000 requests per second.) With passive checking, in contrast, failure detection speed is proportional to request rate.
But there’s one major downside to pure passive healthchecking. If a server goes down, the load balancer will quickly remove it from service. That means no more traffic, and no more traffic means that the client’s view of the server’s health never changes: It stays at zero forever.
There are ways to deal with this, of course, some of which also address other no-data edge cases such as client startup or replacing a single server in the client’s server list. All of these need to be specially addressed if using passive checking.

HEALTH WRAP-UP
Summing up the above:
- Passive monitoring of traffic necessarily gives a more comprehensive and nuanced view of health than active checks
- There are multiple axes along which to evaluate health
- A server’s health can only be understood relative to the cluster
But what do we do with that information? How can all these real-valued numbers be combined to meet our goals of lower latency, minimal failures, and evenly spread load?
I’d like to first take a digression into a family of failure modes, then discuss some common health-aware load balancing approaches, and finally list some possible future directions.
Uncoordinated action can have surprising consequences. Imagine that a large corporate office sends out an email to employees: “We’re offering massages for all employees in auditorium 2 today! Come by whenever.” When do you think people will show up? My guess is that there would be big crowds at a few times of day:
- Right away
- After lunch
- Late afternoon before going home
With this uneven distribution, the massage therapists sometimes have no one to work on; at other times, there are long enough lines that people give up, maybe not even trying again later. Neither of these are desirable. Without any coordination at all—because there’s no coordination—people somehow still show up in groups! The accidental correlated behavior in this scenario is easy to prevent using a commonplace tool: The sign-up sheet. (In software land, the closest analog would be a batch processing system that accepts jobs, schedules them at its own convenience, and returns the results asynchronously.)
It turns out there are a number of similar phenomena in API traffic, often grouped together under the moniker of the thundering herd problem. A classic example is a cache service which is consulted by hundreds of application nodes. When the cache entry expires, the application needs to recreate the value with fresh data, and doing so requires both extra work and (likely) extra network calls to other servers. If hundreds of app nodes simultaneously observe a popular cache entry expiring (because they are all constantly receiving requests for this data) then they will all simultaneously attempt to recreate it, and simultaneously call the backend services responsible for producing fresh data. This is not only wasteful (best case, only a single app node should perform this task, once per cache lifetime) but it could even crush the backend servers, which are normally sheltered behind the cache.
The classic solution for thundering herd problems in cache expiry is to probabilistically expire the cache entry early on a per-caller basis, rather than having it expire at the same instant everywhere. The simplest approach is to add jitter, a small random number subtracted from the expiration date whenever the client consults the cache. A refinement of this technique, XFetch, biases the jitter to delay refresh to the last possible moment.
Another familiar problem occurs when a large number of users of a service set up a periodic task to call an API. Perhaps every user of a backup service installs a cron job to upload a backup at midnight (either in their local time zone, or more likely in UTC.) The backup server then gets overloaded at midnight UTC and is largely unused during the day.
Again, there’s a standard solution: When onboarding a new user, generate a suggested crontab file for them to install, using a randomly selected time for each user. This can even work without a central point of coordination if the backup software itself writes the crontab file, selecting a random time when first installed. (You might notice that a similar approach could work for the massage scenario if a central sign-up sheet couldn’t be used for some reason: Employees each randomly pick a time of day when they’re free, and go at that time, even if it’s not necessarily the optimal time for their own schedule.)
These two solutions—jittered expiry and randomized scheduling—both make use of randomness as a counter to uncoordinated yet correlated behavior. This is an important principle: Randomness Inhibits Correlation. We’ll see this come up again when addressing some challenges relevant to load balancing.
We also see, from the massage scenario, an alternative approach of relying on a central point of coordination. This is one advantage of using a small cluster of powerful servers for a dedicated load-balancer—each server has a higher-level view of the traffic flow than each of a larger number of clients would have. Another way to increase coordination is to have servers self-report utilization as parasitic metadata in their responses. This is not always possible, but server-reported utilization gives clients aggregated information that they would not otherwise have access to. This could give client-side load balancers a more-global view of the sort a dedicated load balancer might have. As a bonus, it may help at times to distinguish between server and network failures, with implications for load-dependent vs. load-independent interpretations.
With this aspect of system dynamics in mind, let’s return to looking at how load balancers use health information.
USING HEALTH IN LOAD BALANCING
Load balancers commonly separate usage of health information into two concerns:
- Deciding which servers are candidates for requests, and then
- Deciding which candidate to select for each request
The classic approach treats these as two totally separate tiers. AWS’s ELB, ALB, and NLB for instance use a variety of algorithms for spreading load (random, round-robin, deterministic random, and least-outstanding) but there is a separate mechanism, largely based on active healthchecks, for determining which servers can participate in that selection process. (Based on the docs, it sounds like NLBs will also use some passive monitoring to decide whether to kick a server out, but details are scarce.)
Random, round-robin, and deterministic random (such as flow-hash) completely ignore health: A server is either in or out. The least-outstanding algorithm, on the other hand, uses a passive health metric. (Note that even this algorithm for server selection is kept totally separate from the active checks used for taking servers out of the cluster.) Least-outstanding (“pick server with lowest request concurrency”) is one of several approaches for using passive health metrics for allocating requests, each based on optimizing one of the metrics mentioned earlier: Latency, failure rate, concurrency, queue size.
SELECTION ALGORITHMS
Some load balancing selection algorithms choose the server with the best value for a metric. On its face, this makes sense: This gives the current request the best shot at succeeding, and quickly. However, it can lead to what I term mobbing: If latency is the health metric of choice and one server exhibits slightly lower latency than the others (as seen from all clients), then all of the clients will send all of their traffic to that one server—at least until it begins to suffer from the load, and possibly even starts to fail. As the server begins to suffer, its effective latency increases, and possibly a different server gains the title of globally healthiest. This may repeat cyclically, and be instigated by nothing more than a very slight difference in initial health.

Mobbing behavior involves a confluence of several defects in the system:
- Latency is a delayed health metric. If concurrency (in-flight request count) were used instead, clients would not mob, since the concurrency metric is instantly updated at the client side as soon as more requests are allocated to a server. Delayed measurements, even with damping, can lead to undesirable oscillation or resonance.
- Clients do not have a global view of the situation, and are therefore acting in an uncoordinated fashion to produce unwanted correlated behavior.
- A small difference in server health produces a large difference in load balancing behavior. Since there are feedbacks from the latter to the former, this fits one description of chaotic systems, which are highly sensitive to initial conditions.
The remedies, as I see them:
- Use fast health metrics where possible. Indeed, a very common load balancing selection algorithm is to send all requests to the server with the least in-flight requests. (Sometimes called least-connections or least-outstanding, depending on whether it is connection or request oriented—some connections are long-lived and carry many requests over their lifetime.) In contrast, I don’t believe I’ve seen a pick-least-latency algorithm, probably for this very reason.
- Either attempt to approximate a global view of the situation (by using a dedicated load balancer with a small number of servers, or incorporating server-reported utilization) or use randomness to inhibit unwanted correlated behavior.
- Use algorithms that have approximately the same behavior for approximately the same inputs. They don’t have to have continuously-variable behavior, but can use randomness to achieve something approximating it.
There’s a popular alternative to pick-the-best called two-choice, described in the paper The Power of Two Random Choices, which discusses a general approach to resource allocation (not specific to or even centered on load balancers, but certainly relevant). In this approach, two candidates are selected and the one with the better health is used. This approximates an even distribution when the long-term health of all the servers approach an identical value, but even a small persistent difference in health can vastly unbalance the load distribution. A simplistic simulation with no feedbacks illustrates this:
;; Select the index of one of N servers with health ranging ;; from 1000 to 1000-N, +/-N (defn selecttc [n] (let [spread n ;; top and bottom health ranges overlap by ~half ;; Compute health of a server, by index health (fn [i] (+ (- 1000 i spread) (* 2 spread (rand)))) ;; Randomly choose two servers, without replacement [i1 i2] (take 2 (shuffle (range n)))] ;; Pick the index of the healthier server (if (< (health i1) (health i2)) i2 i1)))
;; Run 10,000,000 trials with 5 hosts and report the number of times ;; each host index was selected (sort-by key (frequencies (repeatedly 10000000 #(selecttc 5)))) ;;= ([0 2849521] [1 2435167] [2 2001078] [3 1566792] [4 1147442])
Assuming the increased load didn’t affect the health metric, this would produce a 2.5x difference in request load between the healthiest and unhealthiest when the hosts have even an approximate ranking of health. Note that host 0’s health range is 995–1005 and host 4’s is 991–1001; despite being only 1–2% apart in absolute terms, this slight bias is magnified into a large imbalance in load.
While two-choice reduces mobbing (and does quite well when no bias is present, which may well be the case if feedbacks occur), it’s clear that this is not an appropriate selection mechanism to use with delayed health metrics. Additionally, the paper appears to be focused on max load reduction given an identical set of options, which is not the case for health-aware load balancers.
On the other hand, two-choice works well with least-outstanding because the feedback is both instantaneous and self-correcting. Least-outstanding is itself challenging in potentially having small, quantized values. Is a server with one open connection twice as healthy as a server with two? How about zero and one? Least-outstanding is easier to work with if there are relatively few clients (such as in a dedicated load balancer) in relation to the request load, resulting in easier comparisons (e.g., 17 vs. 20.) With small average values, randomization as a tie-breaker becomes very important, lest the first server in the list always receive requests by default—if each client only has one connection open, but there are 300 clients, they may collectively mob that one server. Two-choice, with its randomization, presents itself as a natural antidote for mobbing resulting from least-outstanding’s small discrete values.
A very promising option, though still academic, is weighted random selection. Each server is assigned a weight derived from its health metrics, and a server is picked according to that weight. For instance, if servers had weights 7, 3, and 1, they would have a 70%, 30%, and 10% chance of being selected each time, respectively. Use of this algorithm requires care to avoid the starvation trap, and weight derivation needs to use a well-chosen non-linear function so that a server at 90% of the health of the others receives a greatly reduced weight, perhaps only 20% relative. At work, I’m experimenting with this approach, and I have high hopes for it after some local integration experiments, but I haven’t yet seen it tested with real-world traffic. If it pans out, I’ll likely go into more detail in a future post on a new load-balancing algorithm.
COMBINING HEALTH METRICS
I’ve been putting off the question of how to use multiple health metrics. To my mind, this is the hardest part, and it cuts to the core of the whole matter: How do you define health for your application?
Let’s say you’re tracking latency, failure rate, and concurrency, because all of these matter to you. How do you combine them? Is a 5% failure rate just as bad as a 10x increased latency? (100x?) At what point would you rather take your chances with a 90% available server when the other one is showing massive latency spikes? Two general strategies come to mind.
You might take a tiered approach, by defining thresholds of acceptability for each metric, and picking only from servers with acceptable failure rates; if there are none, pick from those with acceptable latency, etc. Maybe you have a spillover threshold defined so that if the acceptable pool is too small, servers from the next tier down are considered as well. (This idea bears some resemblance to Envoy’s priority levels.)
Alternatively, you could use merged metrics, in which the metrics are combined according to some continuous function. Perhaps you put more weight on some. I’m currently experimenting with deriving a [0,1] weight factor for each health metric, and multiplying them together, with some raised to higher powers (squared or cubed) to give them more weight. (I suspect that very large powers could be used to implement something like the tiered approach even while using a merged metrics combiner).
It’s also worth considering how these metrics might co-vary, suggesting possible benefits from more advanced modeling of server and connection health. Consider a server that has entered a bad state and is spewing failure responses very quickly. If the only health metric is latency, this server now looks like the healthiest in the cluster, and therefore receives more of the traffic. rachelbythebay calls this the load-balanced capture effect. Fast is not always healthy! Depending on your configuration, a merged approach may or may not sufficiently suppress traffic to this rogue server, while a tiered approach that prioritizes low failure rate would exclude it entirely.
Latency and failure rate, in general, are tied up with each other in non-obvious ways. Besides the “spewing failures quickly” scenario, there’s also the matter of timeout vs. non-timeout failures. Under high latency conditions, the client will produce a number of timeout errors. Are these “failures,” per se, or just excessively high-latency responses? Should they affect the latency metric, the failure rate metric, or both? Compare with failures due to bad DNS records and other fast connection failures. My recommendation is to only record latency numbers from successes, or from failures which you know indicate a timeout, such as SocketTimeoutException and similar in Java. (A coworker suggests an alternative of only recording latency values for failures when it makes the latency average worse.)
LIFECYCLE
The above mostly assumes the client is talking to a static collection of servers. But servers are replaced, either one at a time or in large groups. When a new server is added to the cluster, the load balancer should not hit it with a full share of traffic right away, but instead ramp up the traffic slowly over some period. This warm-up period allows for the server to become fully optimized: Disk and instruction cache warming, hotspot optimization in Java, etc. HAProxy implements a slow-start to this end. Beyond warm-up, this is also a time of uncertainty: The client has no history with the server, so limiting dependence on it can limit risk.
If you’re using a metric-combination approach, it may be convenient to use server age as a pesudo-health metric, starting from near zero and ramping up to full health over the course of a minute or so. (Starting from precisely zero may be dangerous, depending on your algorithm; the client may learn of the complete replacement of a set of servers all at once, or be reconfigured to point to a different cluster, and briefly consider all servers to be at zero health). It’s likely that any mechanism for handling total replacement of the server list will also suffice to handle client startup, as well.
LOAD SHEDDING
I only lightly touched on load shedding, in which a service under heavy request load attempts to respond to some or all requests with failures, very quickly, in an effort to reduce CPU load and other resource contention. Sometimes your best effort just isn’t enough, or you just need to keep the service alive long enough that it can be scaled out. Load shedding is a gamble predicated on the idea that returning failures for 50% of traffic now might allow you to respond successfully to 100% of traffic later, and that trying to handle all traffic right now might take down the service entirely. How do you know when to do it, though, and how much?
I suspect this is largely a separable concern: If the load balancer is good enough at distributing load, simply putting something like Hystrix or concurrency-limits in front might be sufficient. The one place I could see benefit would be in managing the additional load on healthy servers when some servers are unhealthy. If only 20% of the servers are healthy, is it reasonable that they should take 5x their normal share of the load? A load balancer might reasonably decide to cap the overage at 10x or so, and never ask any one server to take on the “load share” of 9 servers that have been marked as unhealthy. While this is feasible, is it desirable? I’m not sure. It’s not fully adaptive, in the sense that an overage cap still has to be configured, and that configuration can easily fall out of date (or be irrelevant, e.g., in a low-traffic period).
CONCLUSIONS
Based on the above, I believe that while many of the existing options for load-balancing in generic, high-availability environments tend to work well for distributing load under normal conditions and in a select set of error conditions, they variously fall short under other conditions due to mobbing, insufficient responsiveness to failure, and overreaction to correlated degraded states.
An ideal high-availability load balancer would eschew active healthchecks for its normal operation, and instead passively track a variety of health metrics, including current in-flight requests and decaying (or rolling) metrics of latency and failure rate. A client tracking these metrics is in a far better position to perform anomaly detection than one only observing periodic active healthcheck results.
Of course, a truly ideal load balancer would embody perfect efficiency, in which even under increasing request load all requests are handled as successfully and quickly as possible… right up until the system reaches its theoretical limit, at which point it suddenly fails (or starts shedding load), rather than gradually showing increasing stress. While I would file this under “problems I’d love to have,” it does highlight the need to review monitoring tools if the load balancer is particularly good at hiding server failures from the outside world.
The main open question, in my mind, is how to combine these health metrics and use them in server selection in a way that minimizes chaotic behavior and the other issues mentioned in this post, while still remaining generally applicable. While I’m currently betting on multi-factor weighted random selection, it still remains to be seen how it performs in the real world.